HBM이란 — AI 반도체의 심장이 된 고대역폭 메모리
GPU의 진짜 병목은 연산이 아니라 메모리 대역폭이다. D램을 위로 쌓아 GPU 옆에 붙인 HBM이 왜 AI 시대의 핵심 부품이 됐는지, 세대 구분과 SK하이닉스·삼성·마이크론 3사 구도까지 한 번에 정리했다.

엔비디아 GPU 한 장 가격의 절반 가까이가 메모리값이라는 말을 들으면 대부분 의아해한다. 연산을 하는 건 GPU인데 왜 메모리가 그렇게 비싼가. 답은 간단하다. AI에서 GPU의 발목을 잡는 건 계산 속도가 아니라 데이터를 얼마나 빨리 퍼 나르느냐다. 그 병목을 푸는 부품이 바로 HBM이고, 지금 이 시장을 가진 회사는 전 세계에 셋뿐이다.
처음 HBM 설명을 듣고 “그냥 비싼 램 아니냐”고 넘겼다면, 정확히 그 오해를 푸는 게 이 글이다.
🧠 HBM이 뭐냐 — 한 줄로 먼저
HBM(High Bandwidth Memory, 고대역폭 메모리)은 D램 칩을 수직으로 쌓아 올려 GPU 바로 옆에 붙인 메모리다. 핵심은 두 가지뿐이다. 쌓는다, 그리고 옆에 붙인다.
우리가 흔히 아는 PC 메모리(DDR)는 칩을 기판에 평평하게 한 줄로 깔고, 프로세서와는 제법 떨어진 자리에 꽂힌다. HBM은 그 칩들을 아파트처럼 위로 8단, 12단 쌓은 뒤, GPU와 같은 기판(인터포저) 위에 나란히 올린다. 거리가 가까워지니 둘을 잇는 길을 훨씬 넓게 뚫을 수 있다.
메모리를 위로 쌓고, 길을 넓히고, GPU 옆에 붙인다 — HBM의 정체는 이 한 문장이 전부다.
비유하자면 이렇다. 일반 D램은 좁은 골목으로 트럭이 한 대씩 오가는 구조다. HBM은 그 골목을 차선 수십 개짜리 고속도로로 바꾼 것이다. 트럭 한 대의 속도(개별 칩 속도)는 비슷한데, 한 번에 보내는 양이 차원이 다르다.
🚗 왜 AI가 HBM에 목을 매나
거대 언어모델은 수천억 개의 파라미터를 메모리에 올려두고, 토큰 하나를 뱉을 때마다 그 값을 통째로 읽어 들인다. 연산 자체는 GPU가 눈 깜짝할 새 끝낸다. 문제는 그 연산에 먹일 데이터가 제때 도착하느냐다. 데이터가 늦으면 비싼 연산 유닛이 그냥 논다. 반도체 업계가 메모리 월(memory wall) 이라 부르는 오래된 골칫거리다.

그림처럼 같은 D램이라도 길의 너비가 다르다. 일반 DDR5 모듈 하나가 초당 수십 기가바이트(GB)를 나르는 동안, HBM은 스택 하나가 초당 1테라바이트(TB)를 넘긴다. 게다가 GPU 한 장에는 보통 이 스택이 여러 개 붙는다. 합치면 초당 수 테라바이트, 일반 메모리와 자릿수가 달라진다.
연산 유닛이 아무리 많아도 데이터가 안 오면 논다. AI 시대에 대역폭이 곧 성능인 이유다.
🏗️ 그런데 왜 만들기가 어려운가
쌓는다는 말은 쉽지만, 실제로는 머리카락보다 얇은 D램을 수직으로 정렬해 붙이는 일이다. 칩과 칩 사이를 전기적으로 잇기 위해 실리콘에 미세한 구멍을 뚫어 기둥을 세우는데, 이걸 TSV(실리콘 관통전극) 라 부른다. 수천 개의 기둥이 단 하나라도 어긋나면 그 스택은 불량이다.
여기에 문제가 더 있다. 칩을 빽빽이 쌓으면 열이 안에 갇힌다. 발열을 못 잡으면 성능이 떨어지거나 수명이 준다. 그래서 HBM은 단순히 D램을 잘 만드는 기술이 아니라, 쌓고·뚫고·붙이고·식히는 패키징 기술의 총합이다. 진입 장벽이 높은 건 바로 이 지점 때문이고, 그래서 만드는 회사가 손에 꼽힌다.
🔢 세대 구분 — 숫자가 빠르게 올라간다
HBM은 세대를 거치며 용량과 대역폭을 계속 키워 왔다. 이름만 알아두면 기사 읽기가 한결 쉬워진다.
- HBM2 / HBM2E — HBM을 대중화시킨 세대. 초기 AI 가속기에 쓰였다.
- HBM3 — 대역폭이 스택당 800GB/s 안팎으로 뛴 세대. 본격적인 AI 학습용 GPU의 표준이 됐다.
- HBM3E — 현재 주력. 스택당 1TB/s를 넘기고 용량도 커졌다. 최신 AI 가속기 대부분이 이걸 쓴다.
- HBM4 — 다음 세대. 길을 더 넓히고(버스 폭 확대), 스택 맨 아래의 베이스 다이를 고객 맞춤형으로 설계하는 방향으로 간다.
세대가 올라갈수록 단순히 빨라지기만 하는 게 아니라, GPU 회사와 메모리 회사가 설계 단계부터 함께 맞추는 쪽으로 바뀌고 있다. HBM4에서 베이스 다이를 커스텀한다는 게 그 신호다. 메모리가 범용 부품에서 맞춤 부품으로 넘어가는 중이다.
🏭 만드는 곳은 셋뿐 — 그래서 한국이 중요하다
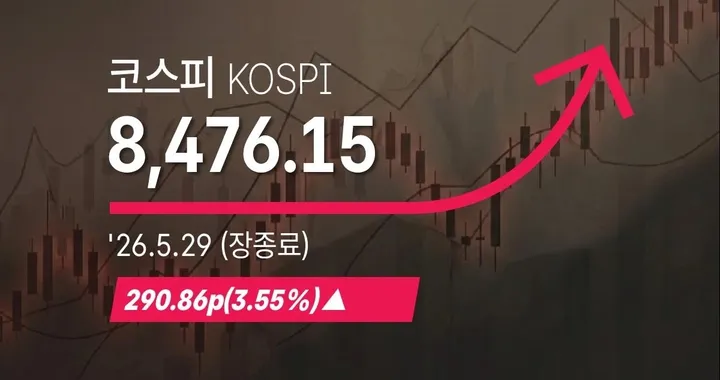
전 세계에서 HBM을 양산하는 회사는 SK하이닉스·삼성전자·마이크론, 단 셋이다. 그중 둘이 한국 기업이라는 점이 코스피 반도체 장세의 배경을 만든다.
- SK하이닉스 — HBM3E 시장의 선두로 평가받는다. 엔비디아라는 최대 고객을 일찍 잡은 게 컸다.
- 삼성전자 — 메모리 1위의 저력으로 추격 중. HBM에서의 점유율 회복이 주가의 핵심 변수로 꼽힌다.
- 마이크론 — 미국 업체로 후발이지만 빠르게 따라붙고 있다. 마이크론 실적이 다음 날 삼성·하이닉스 주가를 흔드는 풍향계 역할을 하는 이유다.
코스피가 신고가를 써도 지수를 끌어올린 건 사실상 이 메모리·AI 반도체 쏠림이었다. 같은 맥락은 반도체 빼면 지수가 없다에서 따로 짚었다. 누가 다음 세대 HBM을 먼저, 더 잘 만드느냐가 곧 이 종목들의 실적과 주가를 가른다.
🔭 비싸고, 뜨겁고, 그래도 계속 큰다
HBM의 약점은 분명하다. 만들기 어려운 만큼 비싸고, 발열 부담이 크고, 수요가 폭발하면서 한동안 만성적인 공급 부족에 시달렸다. 가격이 비싸다는 건 메모리 회사엔 마진이지만, 그만큼 AI 인프라 전체의 원가를 끌어올리는 요인이기도 하다.
그럼에도 방향은 한쪽이다. 모델이 커지고 추론 수요가 늘수록 대역폭에 대한 갈증은 더 심해진다. 엔비디아 젠슨 황이 방한해 HBM이 아니라 ‘로봇’을 강조한 것도, 역설적으로 HBM 공급이 이제 당연한 전제가 됐다는 방증에 가깝다. 그리고 차세대 HBM에서 패키징·검사 공정의 중요성이 커지면서, 메모리 3사를 넘어 후공정 소부장으로 수혜가 번지는 흐름도 같이 봐야 한다.
✅ 정리하면
HBM은 D램을 쌓아 GPU 옆에 붙여 길을 넓힌 메모리다. AI에서 성능을 가르는 건 연산이 아니라 데이터를 나르는 속도이고, 그 속도를 책임지는 부품이라 값이 비싸도 없어서 못 판다. 만드는 회사가 셋뿐, 그중 둘이 한국 기업이라는 사실이 지금 국내 증시의 무게중심을 설명한다.
다음에 “HBM 공급이 풀렸다” 같은 헤드라인을 만나면, 그게 단순한 부품 뉴스가 아니라 AI 가속기 한 대가 더 만들어질 수 있느냐의 문제라는 걸 떠올리면 된다.
관련 글